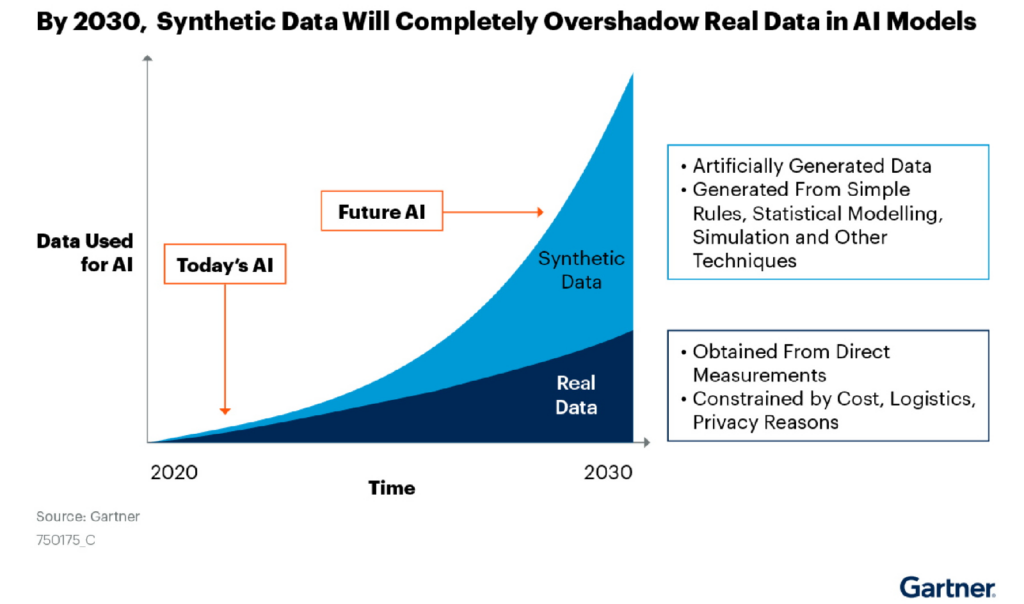
4. Few-shot Learning: Learning from Limited Labelled Data
When it comes to developing AI, there’s often a challenge of not having enough labelled data. But there’s a solution called few-shot learning that tackles this challenge with the help of artificial visual data generation. This approach involves training models using only a small number of labelled examples. Artificial datasets are created to cover different situations and difficult cases, which helps AI models learn effectively even when there’s not much labelled data available.
Recent studies have shown that few-shot learning with artificial data can significantly improve accuracy, with up to an 80% improvement compared to models trained only on a limited amount of real-world data. This highlights the important role of artificial visual data in overcoming the problem of not having enough labelled data in AI development.
5. Continuous Learning: Adapting to Ever-changing Environments
In dynamic environments, AI systems need to keep learning and adapting from new data. Artificial visual data generation helps with this by providing a constant flow of different and labelled datasets.
This approach allows AI models to stay up to date and adjust to changes without relying only on real-world data. Companies that use continuous learning with artificial data have seen up to a 30% decrease in the time it takes to retrain their models when they encounter new situations.
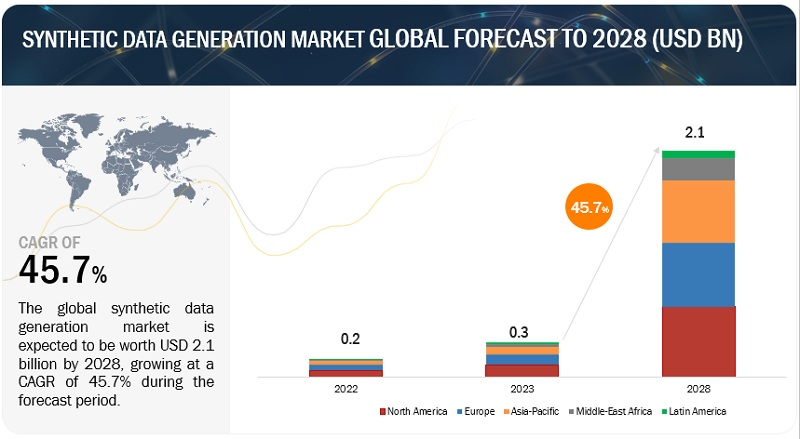
Source: https://www.marketsandmarkets.com/Market-Reports/synthetic-data-generation-market-176419553.html
The way we train artificial intelligence is changing. Instead of relying solely on real data, we’re now using artificial visual data to teach AI models. This new approach is transforming the field of AI development.
By using advanced techniques like hyperrealism, domain adaptation, data augmentation, few-shot learning, and continuous learning, we’re able to create more accurate and high-performing AI models. These innovations in visual synthetic data generation are reshaping the future of AI.
The impact of using synthetic data is clear. It leads to better accuracy and improved performance for AI models. As we continue to advance in visual synthetic data generation, we can expect even more realistic and diverse datasets. This will enable AI models to excel in complex real-world situations. It’s an exciting time for training data, with visual synthetic data generation leading the way in driving innovation in AI.