For decades, traditional datasets have been the foundation of machine learning. These datasets are created by people manually labelling or carefully collecting real-world images, videos, or sensor data that show different situations.
Traditional datasets have been really useful in training models for tasks like recognizing objects or dividing them into parts in computer vision. But even though they are valuable, traditional datasets have their own limitations.
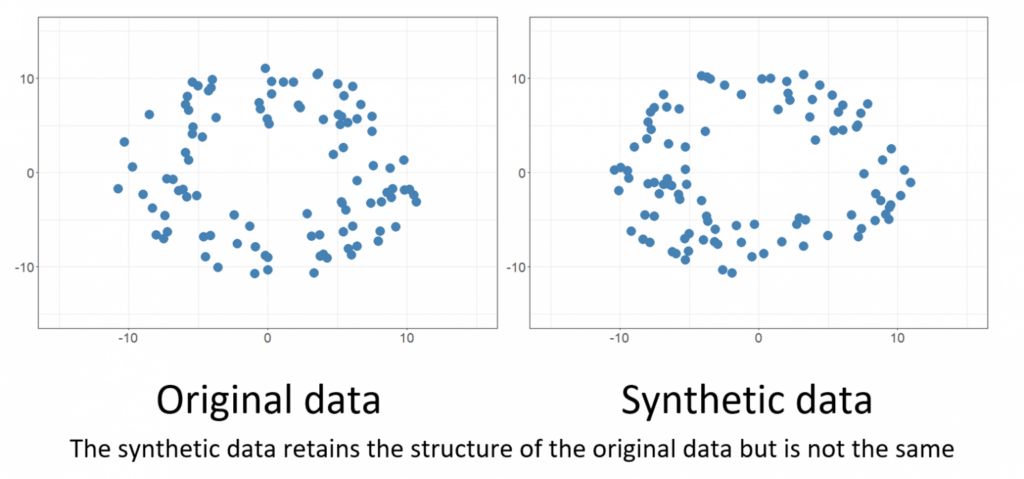
Source: https://research.aimultiple.com/synthetic-data-vs-real-data/
Limited Diversity: Traditional datasets often lack diversity when it comes to objects, backgrounds, lighting, and angles. This can make it difficult for models to handle real-life situations that weren’t well-represented in the training data.
Cost and Time: Collecting and labelling large-scale traditional datasets can be a time-consuming and expensive process. It requires significant resources, human effort, and expertise. Plus, there may be privacy concerns or logistical challenges in obtaining real-world data.
Visual Synthetic Data: Visual synthetic data, also known as artificially generated data, is a newer approach that uses computer graphics and simulation techniques to create datasets with lots of variety. By using 3D models, rendering engines, and physics simulations, virtual environments can be made to look like real-life situations.
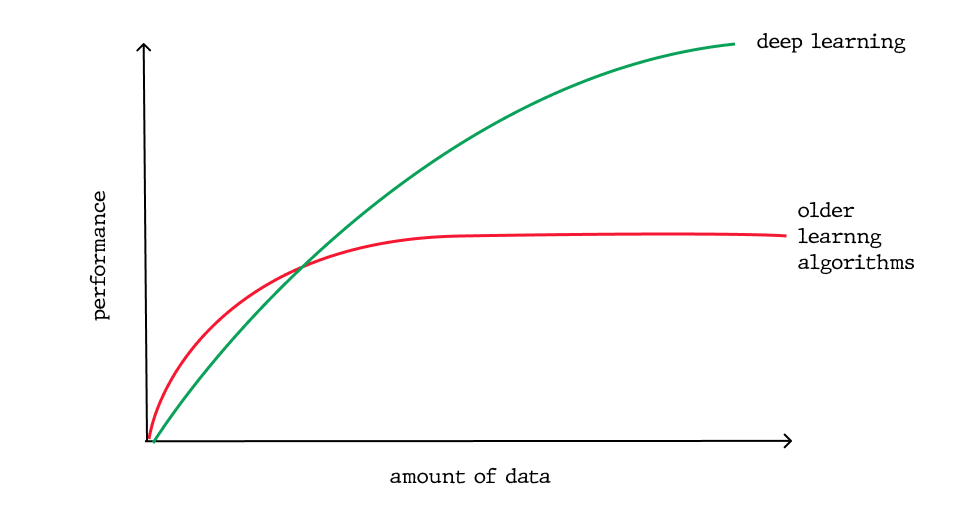
Source: https://soshace.com/deep-learning-vs-machine-learning-overview-comparison/
Unlimited Scalability: Visual synthetic data allows us to create an almost unlimited amount of data with different variations and complexities. This means we can train and test models on a wide range of scenarios, helping them learn from a variety of situations.
Enhanced Diversity: With synthetic data, we can make datasets that have a lot of diversity. We can control things like lighting, weather, where objects are placed, and backgrounds. This diversity helps make the model stronger and better at adapting to different situations.
Cost and Time Efficiency: Generating synthetic data is much more efficient in terms of time and cost compared to collecting traditional data. Once we set up the virtual environment and models, creating new data points is as simple as running simulations. This means we don’t have to spend a lot of time manually labeling data.
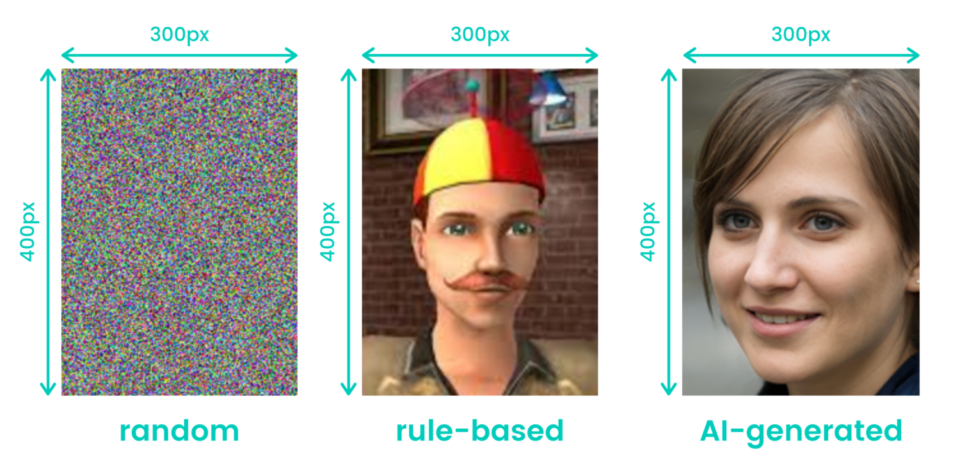
Source: https://mostly.ai/blog/comparison-of-synthetic-data-generation-methods
In the world of training machine learning models, both visual synthetic data and traditional datasets have their own strengths and weaknesses. Traditional datasets use real-world data, while visual synthetic data offers scalability, diversity, and cost efficiency.
By combining both approaches strategically, we can bridge the gap between realism and model performance. This means we can create stronger models that perform well in real-life situations. As technology continues to advance, visual synthetic data holds the promise of revolutionizing the field of machine learning and computer vision.